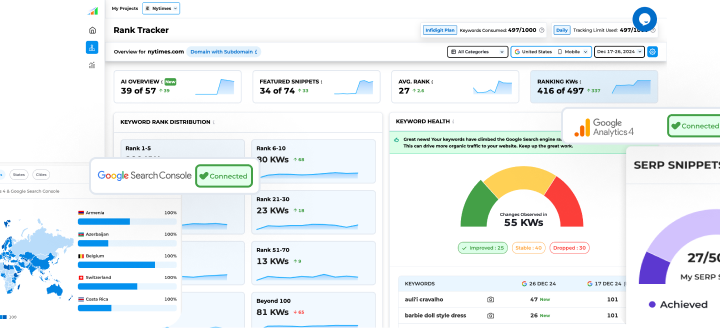







Google has released a new episode on the “Search Off the Record” podcast discussing robots.txt in Google Search
This episode is the 28th episode of the “Search Off the Record” podcast series. The speakers in the episode are Gary Illyes, Lizzi Harvey, and Martin Splitt from the Google Search team who are joined by special guest David Price, a Legal Director at Google.
Who is robots.txt meant for?
Gary Illyes mentioned that Google’s documentation on robots.txt says that robots.txt is meant for crawlers. However, he also raised the question of “what constitutes a crawler?”.
Special guest David Price replied to this by using an example of “Manual vs Automation”.
And so, often when I get this question, I kind of try and think about that manual versus automated question. Is this something that is sort of aligned with something that a user is doing where you have a person in the loop somewhere saying, “Yes, I want to initiate this thing.” And then you want to make sure that you’re not saying it’s a person who’s clicking start to the crawling program, but rather something where you expect to have people in the loop constantly using something and constantly saying, “Well, now I’m interested in this page or that page.” Very much akin to a browser.
And something that’s not that, something that sort of runs with full automation, that is going to be a robot, and if it operates at Google, then it definitely needs to obey robots.txt, said David Prince.
Do social media “bots” follow robots.txt?
Martin Splitt raised a very interesting point about social media bots. He gave an example of a user posting something on social media with a link to an article. He mentioned that once the post is submitted, the social media platform sends an automated request to the URL. The social media bots use this to fetch the Open Graph (OG) tags to display details on the feed. Martin raised the question of whether the social media “robots” follow the robots.txt directives or not.
David prince responded to this question:
“ It’s a good question. …The user said, “Hey, I want to sort of, in some way, engage with this piece of content on the web.” And it’s kind of natural that you would want to look at that content on the web and understand what it is.
And so the social media case, I think, is a good example where you might say that that is not a robot in the classical sense. Now, maybe that then means that there should be some other level of control or some other set of questions. If you are a webmaster, you say, “Hey, I don’t want this fetch to happen.” But the question of “Is it a robot?” I think the answer is probably not.”
Do requests from Google Merchant Center obey the robots.txt file?
Another interesting question asked by Martin Splitt was whether the requests from Google Merchant Center to fetch information from the pages follow robots.txt.
“What if I, as someone who has an e-commerce shop, am opting in to, say, Google Shopping so that Google Merchant Center can make requests. But then these requests happen somewhat outside of my control, because I say, “Yeah, sure you can do that.” But I don’t really request Google to do specific requests to my website.
And then the robot, so to speak, so Google’s product side has to figure that one out. And I think they’ve… Do they follow robots.txt? I guess they do. I don’t know. Maybe not because I, as a website owner, opted in already. Is that a robot?”, asked Martin Splitt.
David Prince replied to this:
“I don’t think anything would stop a webmaster from going out and saying, “Hey, for this particular specific integration that you and I are doing together, I am cool with you going and doing an automated access to my site, regardless of whatever my robots.txt says.
It might be something where a best practice is to adapt your robots file in that situation to account for whatever you’ve agreed to do, so that you have less sort of out-of-band permissions and denials that are not captured in the file. But that is maybe more of an engineering detail than anything else.”
How was robots.txt born?
At the beginning of the Internet, there were robots that were sort of malicious and wrecked havoc among websites by bombarding them with requests. The robots.txt file was introduced to give the webmaster control over these robots and crawlers.
Here are David Prince’s thoughts on the same:
“Because there were robots, especially in the beginning of the Internet, which didn’t necessarily behave well on the Internet, and they were going rampant and ravaging sites. Perhaps that’s also why robots.txt was born, basically giving people some sort of control over these rampant crawlers.
..I think if you kind of think back to the mid-’90s..the state of the technology then was of reasonably limited bandwidth, reasonably limited server capacity, and so you could imagine that somebody with a computer in their dorm room might be able to impose a pretty significant load on a fairly well-known and prominent set of web services at the time. You didn’t have the kind of galactic scale web service systems that you have today.
And so, I think the concern that one sort of ill-behaved script running on somebody’s box under their desk could cause some serious damage to your ability to serve was, I think, a real concern at the time. And if that happened multiple times, and it was scaled across multiple different robots running all over the web, then I think you have, especially in that technological environment, a pretty significant problem.”
There were a lot of other intriguing things discussed in the podcast regarding the robots.txt file. You can hear the entire discussion on the “Search Off the Record” podcast here.
![]()