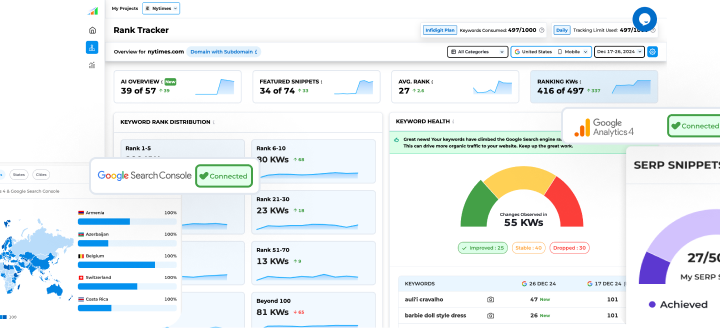







While working on technical SEO, one of the initial things needed to work on is the optimization of the Robots.txt file. It is susceptible to errors. One simple mistake or an unwanted misconfiguration could cause havoc on SEO and all rankings and traffic might go for a toss.
This undeniably small but legitimately crucial file is a part of every website over the internet, but majority of people do not even know about It.
Let’s learn the basics of Robots.txt, what they are, and how they work.
Robots.txt : Overview
Robots.txt is a file that resides in the root directory of your website. It is an instruction manual for search engines crawler to decide which pages or files to request from a site. It basically helps a website from overloading with requests. The first thing search engines seek while visiting a site is to look for and check the contents of the robots.txt file. Depending on the instructions specified in the file, they create a list of URLs they can crawl and index for that website.
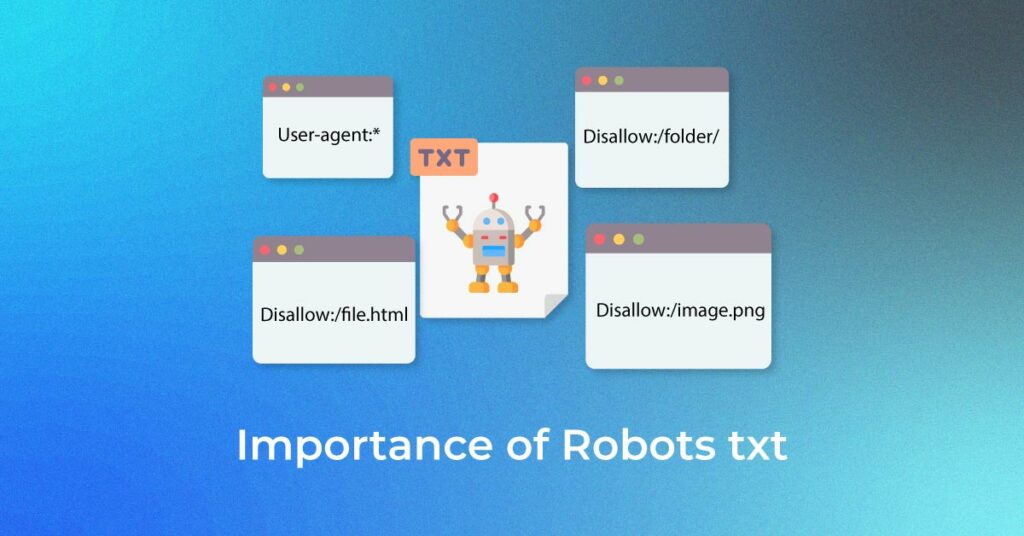
This is How a Robots.txt File Looks Like

Usage of asterisk(*) wildcard makes the work easier as it helps you to assign directives to all user-agents.
Deciphering the Technical Phrases
-
User-agent
Refers to a specific bot to which you give crawl instructions (i.e. search engine).
-
Disallow
Is a command which tells the bot not to crawl a particular URL.
-
Allow
Is a command which tells the bot to crawl a particular URL, even in an otherwise disallowed directory.
-
Sitemap
Helps specify the location of sitemap(s) to the bot. The best practice for this is to place the sitemap directives at the end or beginning of the robots.txt file.
-
Crawl-delay
Helps specify the number of seconds a crawler should wait before crawling the page. Google is no longer considering it, but Yahoo and Bing do.
Placement of Robots.txt File
Technically, you can place robots.txt in any of the main directories of your website. But it is recommended that you should always put it in the root of your domain. For example, if your domain is www.xyz.com, then your robots.txt should be found at www.xyz.com/robots.txt.
It is also crucial to use a lowercase “r” in the file name as robots.txt file is case sensitive. It won’t work otherwise.
Also Read
Importance of Robots.txt file
Whether it is a small website or a large one, it is important to have a robots.txt file. It gives you more control over search engines movement on your website. While a single accidental disallow instruction can cause Googlebot from crawling your entire site, there are some common cases where it can really be handy.
- Prevents server overload.
- Prevents sensitive information from getting exposed.
- Prevents crawl budget from getting wasted.
- Prevents crawling of duplicate content
- Prevents indexing of unnecessary files on your website (e.g. images, video, PDFs).
- Helps to keep sections of your website private (e.g. staging site).
- Prevents crawling for internal search results pages.
Working of Robots.txt
Search engines have two basic jobs to do. First, crawling the web to discover new content. Second, index the found content for users searching for that information.
So, after arriving at a website, the crawler looks for a robots.txt file. When the same is found, the crawler first goes through that file even before spidering your website. As a robots.txt file contains how the crawler should crawl the website, going further without referring to the file would mislead the crawler. If there is no specific mention about the directives that disallow a user-agent’s activity, the crawler will start crawling the other information on the site.
![]()